jerrylee2016 schrieb:Zu seinem Verfahren habe ich noch etwas gefunden, wo er die SD 1.0 , 0.5. und 0.25 definiert. SD = standard deviation =Standard Abweichung ein Begriff aus der Statistik.
jerrylee2016 schrieb:Zu seinem Verfahren habe ich noch etwas gefunden, wo er die SD 1.0 , 0.5. und 0.25 definiert. SD = standard deviation =Standard Abweichung ein Begriff aus der Statistik.
Die SD können aber nun, je nach der Verteilung der einzelnen Daten, z.B. bei einer Normalverteilung, völlig anders sein, bzw. die prozentualem Verteilung. Bei einer Normalverteilung bezieht sich die SD 1.0 auf 68% aller Daten.
Wieso nun z.B. SD 0.5 eine Signalreflexion sein soll, verstehe ich nicht
Ich lese immer nur quer und habe bisher nicht die Zeit und Lust tiefer da einzusteigen , aber das klingt tatsächlich eigenartig. Auch hier:
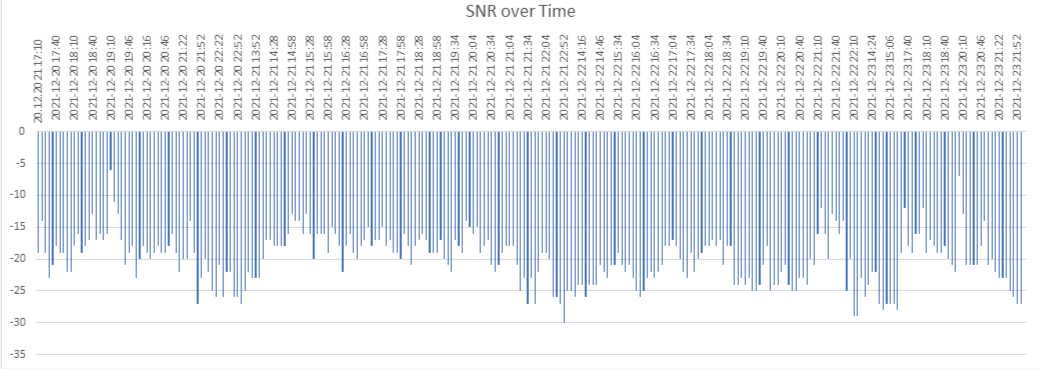
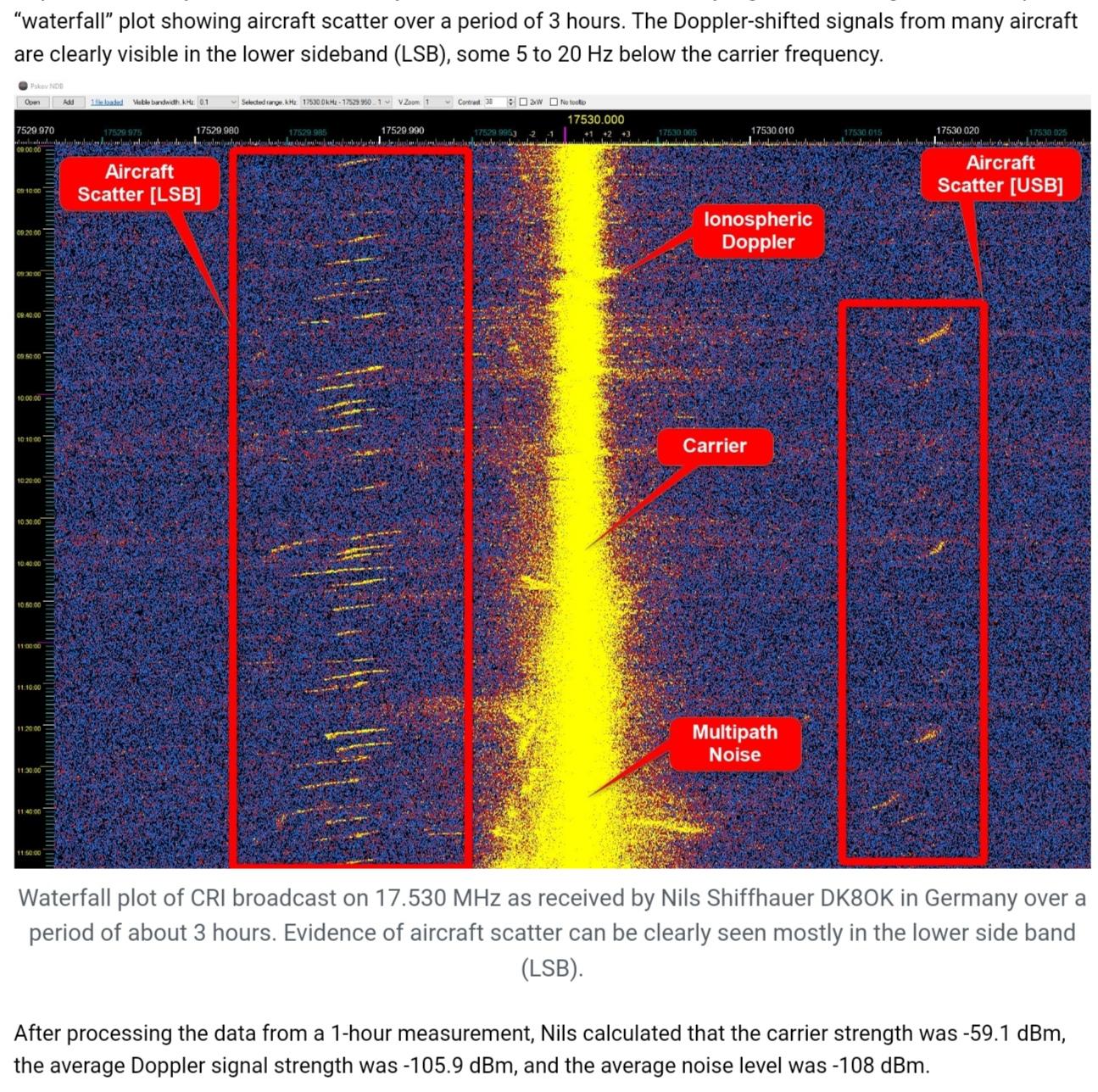
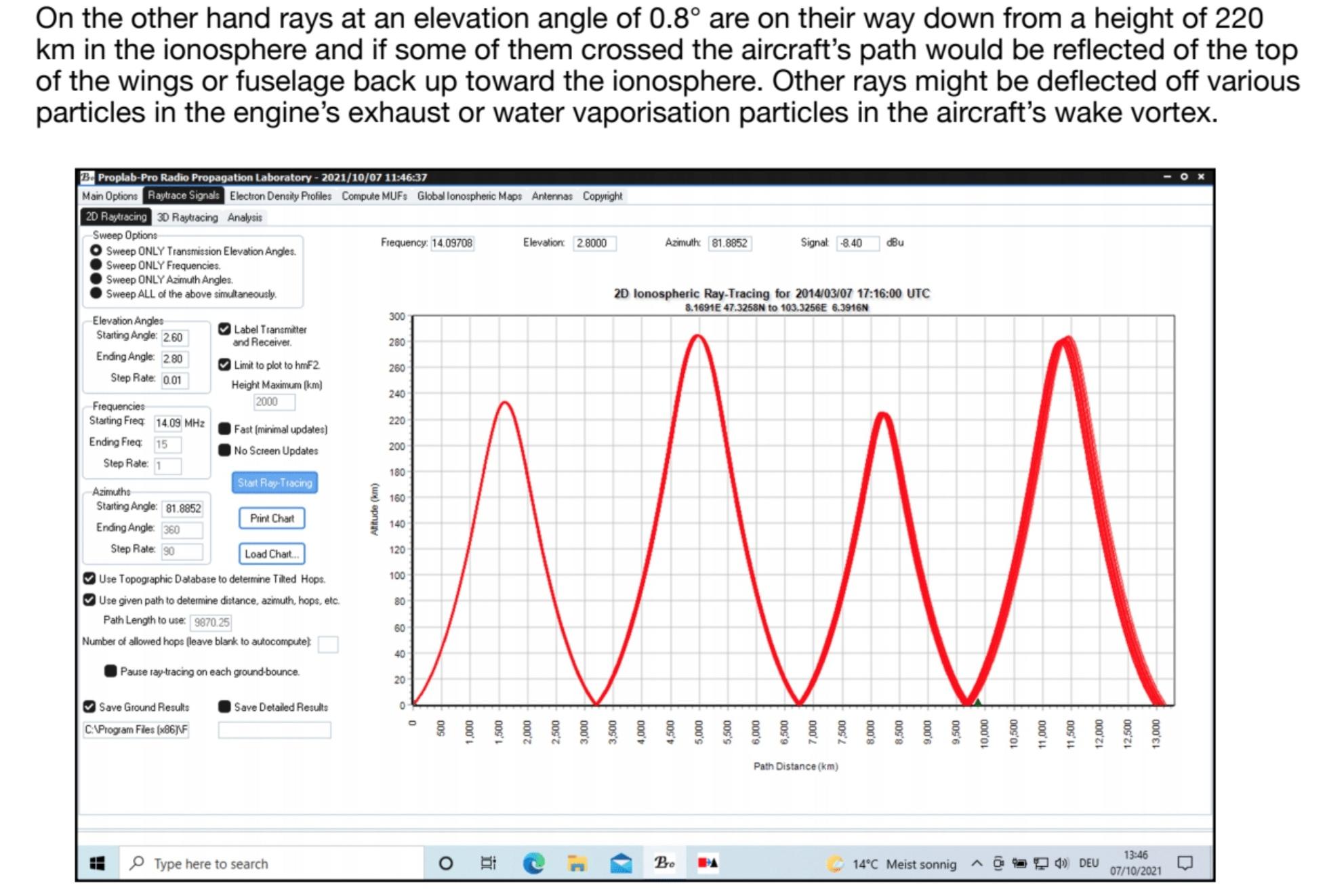
18. Anomalies are both low and high received signal levels as well as both signals with an unusually large deviation and signals with only a small deviation from the mean. Both + 1.0 SD and – 1.0 SD are disturbances, which detect aircraft. But even +0.25 SD and -0.25 SD are also disturbances, which detect aircraft.
Quelle:
https://www.mh370search.com/2021/11/30/mh370-preliminary-findings/comment-page-1/Wenn man mal annimmt die Streuung der Daten (durch zufällige Einflüsse, beim Senden, Empfangen und vor allem natürlich auf den langen Signalwegen mit mehrfacher Spiegelung an Erdoberfläche und der Ionosphäre) seinen normalverteilt (Normalverteilung ist häufig eine gute Annahme, aber auch nicht immer
1)), dann liegen, wie du schreibst, innerhalb des Intevalls -1 SD .. +1 SD gerade mal 68% aller Daten, also 32% bzw. 1/3 liegen außerhalb. Wenn das jetzt ein deutliches Anzeichen für den Einfluss eine Flugzeugs sein soll, dann sind so um 1/3 der Signale durch Flugzeuge gestört? Oder anders gesagt jeder dritte Datenpunkt den er findet wäre von einem Flugzeug gestört. Dann verstehe ich allerdings auch nicht wie man dann eine eindeutige Trajektorie verfolgen können soll.
Und mit -0.25 .. +0.25 SD wird das dann aus meiner Sicht endgültig absurd. Es liegen gut 80% der Daten außerhalb dieses Intervalls (nachzurechnen z.B. in Matlab bzw. der freien Implementierung Octave mit
cdf('Normal',[-0.25,0.25],0,1)). Das heißt 80% der Daten sind nach dieser Auslegung auffällig und weisen auf ein Flugzeug hin. Das macht keinen Sinn. Üblich sind z.B. sogenannte p-Werte von 0.05 (5%) oder noch niedriger wenn es darum geht
signifikante Abweichungen vom Zufall zu definieren. Das wären hier für p=0.05 alles was außerhalb von +/- 1.96 SD vom Mittelwert liegt (Matlab/Octave:
norminv([0.025 0.975])). Und das kann man so eigentlich auch nicht machen wenn man zig, oder hunderte oder gar tausende Werte prüft, denn dass 5% (also jeder zwanzigste) davon außerhalb dieses Intervalls liegt ist ganau das, was man schon aufgrund rein zufälliger EInflüsse erwartet.
Das nur kurz zu dem Punkt, den ich in der Form auch nicht nachvollziehen kann, aber ich habe nicht genug gelesen um den gesamten Ansatz auch nur halbwegs verstanden zu haben und es ist evtl unfair einen einzelnen Punkt in der Form ohne Kontext herauszupicken. Es können nämlich auf der anderen Seite mit geeigneten Modellen (ich nenne mal als Beispiel
Hidden Markov Models HMMs) durch die zeitliche Verknüpfung von kausal abhängigen Daten (Flugzeug, das bereits hier, hier und hier eine Störung verursacht hat muss auch in plausibler Flugrichtung wieder eine Störung verursachen usw.) evtl. durchaus aus sehr unscharfen Einzelereignissen recht plausible Gesamtverläufe geschlossen werden. Ich bin daher durchaus gespannt wie ein Flitzebogen, wie sich das weiterentwickelt...
1) Z.B. können Längen/Größen natürlicher Gegenstände niemals wirklich Normalverteilt sein, da eine Normalverteilung von minus bis plus Undendlich reicht, Dinge aber keine negativen Größen haben können (und auch nicht wirklich unendlich groß sein können). Dann hat man ggf. eine sog.
schiefe Normalverteilung . Häufig hat man auch Überlagerungen mehrerer Normalverteilungen, die zusammen aber keine Normalverteilung mehr sind. Wenn man mit Normverteilung argumentiert muss man also zuerst prüfen, ob es sich annähernd um eine solche handelt, aber das ist hier erstmal gar nicht der entscheidende Punkt (s.o.).